Publications
2025
- Panoptic
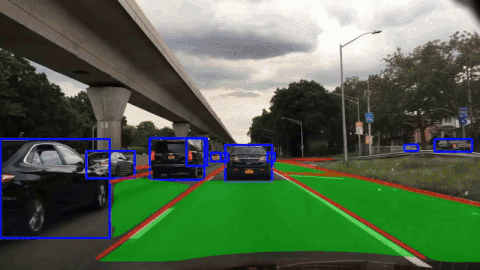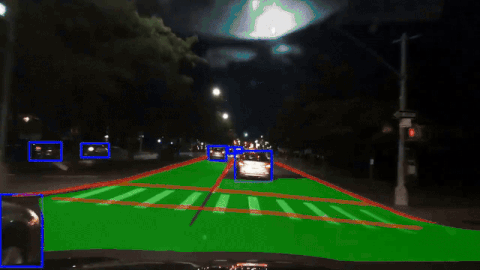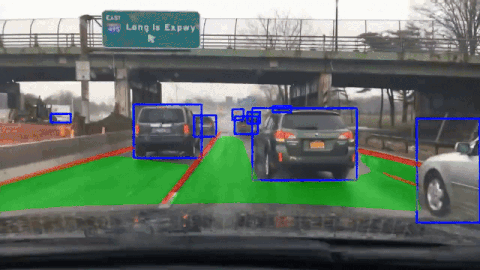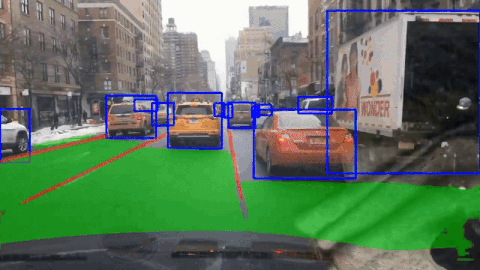 SCAM-P: Spatial Channel Attention Module for Panoptic Driving PerceptionGopi Krishna Erabati, and Helder AraujoIn 2025 IEEE International Conference on Robotics and Automation (ICRA) , 2025
SCAM-P: Spatial Channel Attention Module for Panoptic Driving PerceptionGopi Krishna Erabati, and Helder AraujoIn 2025 IEEE International Conference on Robotics and Automation (ICRA) , 2025A high-precision, high-efficiency, and lightweight panoptic driving perception system is an essential part of autonomous driving for optimal maneuver planning of the autonomous vehicle. We propose a simple, lightweight, and efficient SCAM-P multi-task learning network that accomplishes three crucial tasks simultaneously for panoptic driving: vehicle detection, drivable area segmentation, and lane segmentation. To increase the representation power of the shared backbone of our multi-task network, we designed a novel SCAM module with spatially localized channel attention and channel localized spatial attention blocks. SCAM is a lightweight module that can be plugged into any CNN architecture to enhance the semantic features with negligible computational overhead. We integrate our SCAM module and design the SCAM-P network, which has a shared backbone for feature extraction and three independent heads to handle three tasks at the same time. We also designed a nano variant of our SCAM-P network to make it deployment-friendly on edge devices. Our SCAM-P network obtains competitive results on the BDD100K dataset with 81.1 % mAP50 for object detection, 91.6 % mIoU for drivable area segmentation, and 28.8 % IoU for lane segmentation. Our model is robust in various adverse weather conditions, such as rainy, snowy, and at night. Our SCAM-P network not only achieves improved performance but also runs efficiently in real-time at 230.5 FPS on the RTX 4090 GPU and 112.1 FPS on the Jetson Orin edge device.
@inproceedings{scamp, author = {Erabati, Gopi Krishna and Araujo, Helder}, booktitle = {2025 IEEE International Conference on Robotics and Automation (ICRA)}, title = {SCAM-P: Spatial Channel Attention Module for Panoptic Driving Perception}, year = {2025}, }

2024
- 3DObjDet-LiDAR
 RetFormer: Embracing Point Cloud Transformer with Retentive NetworkGopi Krishna Erabati, and Helder AraujoIEEE Transactions on Intelligent Vehicles, 2024
RetFormer: Embracing Point Cloud Transformer with Retentive NetworkGopi Krishna Erabati, and Helder AraujoIEEE Transactions on Intelligent Vehicles, 2024Point Cloud Transformers (PCTs) have gained lot of attention not only on the indoor data but also on the large-scale outdoor 3D point clouds, such as in autonomous driving. However, the vanilla self-attention mechanism in PCTs does not include any explicit prior spatial information about the quantized voxels (or pillars). Recently, Retentive Network has gained attention in the natural language processing (NLP) domain due to its efficient modelling capability and remarkable performance, leveraged by the introduction of explicit decay mechanism which incorporates the distance related spatial prior knowledge into the model. As the NLP tasks are causal and one-dimensional in nature, the explicit decay is designed to be unidirectional and one-dimensional. However, the pillars in the Bird’s Eye View (BEV) space are two-dimensional without causal properties. In this work, we propose RetFormer model by introducing bidirectional and two-dimensional decay mechanism for pillars in PCT and design the novel Multi-Scale Retentive Self-Attention (MSReSA) module. The introduction of explicit bidirectional and two-dimensional decay incorporates the 2D spatial distance related prior information of pillars into the PCT which significantly improves the modelling capacity of RetFormer. We evaluate our method on large-scale Waymo and KITTI datasets. RetFormer not only achieves significant performance gain over of 2.3 mAP and 3.2 mAP over PCT-based SST and FlatFormer respectively, and 6.4 mAP over sparse convolutional-based CenterPoint for small object pedestrian category on Waymo Open Dataset, but also is efficient with 3.2x speedup over SST and runs in real-time at 69 FPS on a RTX 4090 GPU.
@article{retformer, title = {RetFormer: Embracing Point Cloud Transformer with Retentive Network}, author = {Erabati, Gopi Krishna and Araujo, Helder}, journal = {IEEE Transactions on Intelligent Vehicles}, year = {2024}, } - 3DObjDet-Fusion
 SRFDet3D: Sparse Region Fusion based 3D Object DetectionGopi Krishna Erabati, and Helder AraujoNeurocomputing, 2024
SRFDet3D: Sparse Region Fusion based 3D Object DetectionGopi Krishna Erabati, and Helder AraujoNeurocomputing, 2024Unlike the earlier 3D object detection approaches that formulate hand-crafted dense (in thousands) object proposals by leveraging anchors on dense feature maps, we formulate np (in hundreds) number of learnable sparse object proposals to predict 3D bounding box parameters. The sparse proposals in our approach are not only learnt during training but also are input-dependent, so they represent better object candidates during inference. Leveraging the sparse proposals, we fuse only the sparse regions of multi-modal features and we propose Sparse Region Fusion based 3D object Detection (SRFDet3D) network with mainly three components: an encoder for feature extraction, a region proposal generation module for sparse input-dependent proposals and a decoder for multi-modal feature fusion and iterative refinement of object proposals. Additionally for optimal training, we formulate our sparse detector with many-to-one label assignment based on Optimal Transport Algorithm (OTA). We conduct extensive experiments and analysis on publicly available large-scale autonomous driving datasets: nuScenes, KITTI, and Waymo. Our LiDAR-only SRFDet3D-L network achieves 63.1 mAP and outperforms the state-of-the-art networks on the nuScenes dataset, surpassing the dense detectors on KITTI and Waymo datasets. Our LiDAR-Camera model SRFDet3D achieves 64.7 mAP with improvements over existing fusion methods.
@article{srfdet3d, title = {SRFDet3D: Sparse Region Fusion based 3D Object Detection}, journal = {Neurocomputing}, volume = {593}, pages = {127814}, year = {2024}, issn = {0925-2312}, doi = {https://doi.org/10.1016/j.neucom.2024.127814}, url = {https://www.sciencedirect.com/science/article/pii/S092523122400585X}, author = {Erabati, Gopi Krishna and Araujo, Helder}, keywords = {3D object detection, Fusion, Camera, LiDAR, Autonomous driving, Computer vision}, } - 3DSemSeg
 RetSeg3D: Retention-based 3D semantic segmentation for autonomous drivingGopi Krishna Erabati, and Helder AraujoComputer Vision and Image Understanding, 2024
RetSeg3D: Retention-based 3D semantic segmentation for autonomous drivingGopi Krishna Erabati, and Helder AraujoComputer Vision and Image Understanding, 2024LiDAR semantic segmentation is one of the crucial tasks for scene understanding in autonomous driving. Recent trends suggest that voxel- or fusion-based methods obtain improved performance. However, the fusion-based methods are computationally expensive. On the other hand, the voxel-based methods uniformly employ local operators (e.g., 3D SparseConv) without considering the varying-density property of LiDAR point clouds, which result in inferior performance, specifically on far away sparse points due to limited receptive field. To tackle this issue, we propose novel retention block to capture long-range dependencies, maintain the receptive field of far away sparse points and design RetSeg3D, a retention-based 3D semantic segmentation model for autonomous driving. Instead of vanilla attention mechanism to model long-range dependencies, inspired by RetNet, we design cubic window multi-scale retentive self-attention (CW-MSRetSA) module with bidirectional and 3D explicit decay mechanism to introduce 3D spatial distance related prior information into the model to improve not only the receptive field but also the model capacity. Our novel retention block maintains the receptive field which significantly improve the performance of far away sparse points. We conduct extensive experiments and analysis on three large-scale datasets: SemanticKITTI, nuScenes and Waymo. Our method not only outperforms existing methods on far away sparse points but also on close and medium distance points and efficiently runs in real time at 52.1 FPS on a RTX 4090 GPU.
@article{retseg3d, title = {RetSeg3D: Retention-based 3D semantic segmentation for autonomous driving}, journal = {Computer Vision and Image Understanding}, pages = {104231}, year = {2024}, issn = {1077-3142}, doi = {https://doi.org/10.1016/j.cviu.2024.104231}, url = {https://www.sciencedirect.com/science/article/pii/S1077314224003126}, author = {Erabati, Gopi Krishna and Araujo, Helder}, keywords = {3D semantic segmentation, Retention, Autonomous driving, LiDAR}, } - 3DObjDet-LiDAR
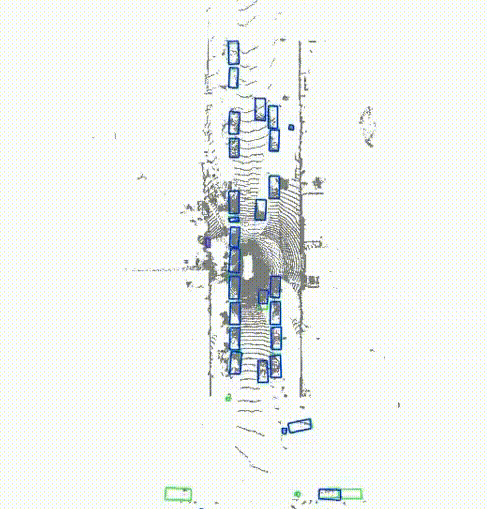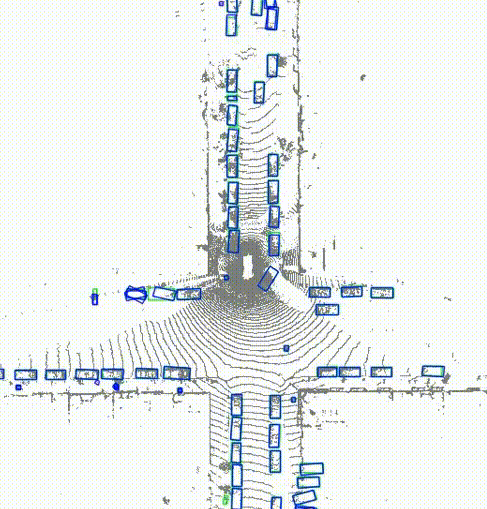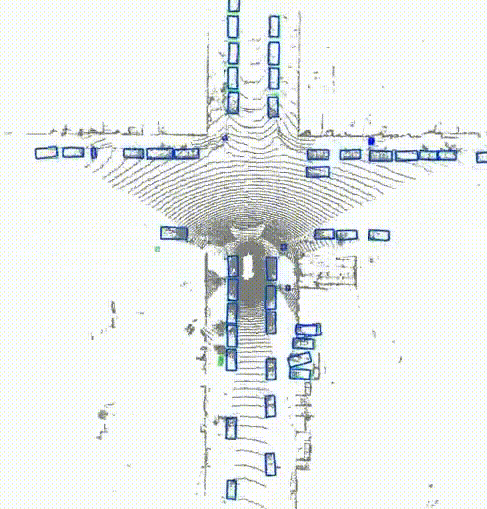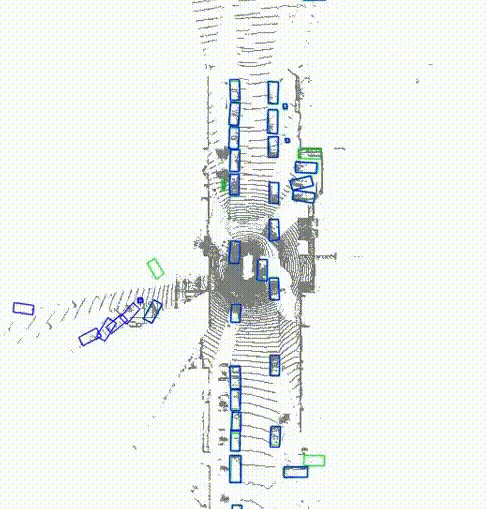 DeLiVoTr: Deep and light-weight voxel transformer for 3D object detectionGopi Krishna Erabati, and Helder AraujoIntelligent Systems with Applications, 2024
DeLiVoTr: Deep and light-weight voxel transformer for 3D object detectionGopi Krishna Erabati, and Helder AraujoIntelligent Systems with Applications, 2024The image-based backbone (feature extraction) networks downsample the feature maps not only to increase the receptive field but also to efficiently detect objects of various scales. The existing feature extraction networks in LiDAR-based 3D object detection tasks follow the feature map downsampling similar to image-based feature extraction networks to increase the receptive field. But, such downsampling of LiDAR feature maps in large-scale autonomous driving scenarios hinder the detection of small size objects, such as pedestrians. To solve this issue we design an architecture that not only maintains the same scale of the feature maps but also the receptive field in the feature extraction network to aid for efficient detection of small size objects. We resort to attention mechanism to build sufficient receptive field and we propose a Deep and Light-weight Voxel Transformer (DeLiVoTr) network with voxel intra- and inter-region transformer modules to extract voxel local and global features respectively. We introduce DeLiVoTr block that uses transformations with expand and reduce strategy to vary the width and depth of the network efficiently. This facilitates to learn wider and deeper voxel representations and enables to use not only smaller dimension for attention mechanism but also a light-weight feed-forward network, facilitating the reduction of parameters and operations. In addition to model scaling, we employ layer-level scaling of DeLiVoTr encoder layers for efficient parameter allocation in each encoder layer instead of fixed number of parameters as in existing approaches. Leveraging layer-level depth and width scaling we formulate three variants of DeLiVoTr network. We conduct extensive experiments and analysis on large-scale Waymo and KITTI datasets. Our network surpasses state-of-the-art methods for detection of small objects (pedestrians) with an inference speed of 20.5 FPS.
@article{delivotr, title = {DeLiVoTr: Deep and light-weight voxel transformer for 3D object detection}, journal = {Intelligent Systems with Applications}, volume = {22}, pages = {200361}, year = {2024}, issn = {2667-3053}, doi = {https://doi.org/10.1016/j.iswa.2024.200361}, url = {https://www.sciencedirect.com/science/article/pii/S2667305324000371}, author = {Erabati, Gopi Krishna and Araujo, Helder}, keywords = {3D object detection, Transformer, Voxel, LiDAR, Autonomous driving, Computer vision}, } - 3DObjDet-LiDAR
 DDet3D: Embracing 3D Object Detector with DiffusionGopi Krishna Erabati, and Helder AraujoApplied Intelligence, 2024
DDet3D: Embracing 3D Object Detector with DiffusionGopi Krishna Erabati, and Helder AraujoApplied Intelligence, 2024Existing approaches rely on heuristic or learnable object proposals (which are required to be optimised during training) for 3D object detection. In our approach, we replace the hand-crafted or learnable object proposals with randomly generated object proposals by formulating a new paradigm to employ a diffusion model to detect 3D objects from a set of randomly generated and supervised learning-based object proposals in an autonomous driving application. We propose DDet3D, a diffusion-based 3D object detection framework that formulates 3D object detection as a generative task over the 3D bounding box coordinates in 3D space. To our knowledge, this work is the first to formulate the 3D object detection with denoising diffusion model and to establish that 3D randomly generated and supervised learning-based proposals (different from empirical anchors or learnt queries) are also potential object candidates for 3D object detection. During training, the 3D random noisy boxes are employed from the 3D ground truth boxes by progressively adding Gaussian noise, and the DDet3D network is trained to reverse the diffusion process. During the inference stage, the DDet3D network is able to iteratively refine the 3D randomly generated and supervised learning-based noisy boxes to predict 3D bounding boxes conditioned on the LiDAR Bird’s Eye View (BEV) features. The advantage of DDet3D is that it allows to decouple training and inference stages, thus enabling the use of a larger number of proposal boxes or sampling steps during inference to improve accuracy. We conduct extensive experiments and analysis on the nuScenes and KITTI datasets. DDet3D achieves competitive performance compared to well-designed 3D object detectors. Our work serves as a strong baseline to explore and employ more efficient diffusion models for 3D perception tasks.
@article{ddet3d, title = {DDet3D: Embracing 3D Object Detector with Diffusion}, author = {Erabati, Gopi Krishna and Araujo, Helder}, journal = {Applied Intelligence}, year = {2024}, } - 3DObjDet-Fusion
 DAFDeTr: Deformable Attention Fusion Based 3D Detection TransformerGopi Krishna Erabati, and Helder AraujoIn Robotics, Computer Vision and Intelligent Systems , 2024
DAFDeTr: Deformable Attention Fusion Based 3D Detection TransformerGopi Krishna Erabati, and Helder AraujoIn Robotics, Computer Vision and Intelligent Systems , 2024Existing approaches fuse the LiDAR points and image pixels by hard association relying on highly accurate calibration matrices. We propose Deformable Attention Fusion based 3D Detection Transformer (DAFDeTr) to attentively and adaptively fuse the image features to the LiDAR features with soft association using deformable attention mechanism. Specifically, our detection head consists of two decoders for sequential fusion: LiDAR and image decoder powered by deformable cross-attention to link the multi-modal features to the 3D object predictions leveraging a sparse set of object queries. The refined object queries from the LiDAR decoder attentively fuse with the corresponding and required image features establishing a soft association, thereby making our model robust for any camera malfunction. We conduct extensive experiments and analysis on nuScenes and Waymo datasets. Our DAFDeTr-L achieves 63.4 mAP and outperforms well established networks on the nuScenes dataset and obtains competitive performance on the Waymo dataset. Our fusion model DAFDeTr achieves 64.6 mAP on the nuScenes dataset. We also extend our model to the 3D tracking task and our model outperforms state-of-the-art methods on 3D tracking.
@inproceedings{dafdetr, author = {Erabati, Gopi Krishna and Araujo, Helder}, editor = {Filipe, Joaquim and R{\"o}ning, Juha}, title = {DAFDeTr: Deformable Attention Fusion Based 3D Detection Transformer}, booktitle = {Robotics, Computer Vision and Intelligent Systems}, year = {2024}, publisher = {Springer Nature Switzerland}, address = {Cham}, pages = {293-315}, isbn = {978-3-031-59057-3}, } - Pose and DepthSelf-supervised monocular pose and depth estimation for wireless capsule endoscopy with transformersNahid Nazifi, Helder Araujo, Gopi Krishna Erabati, and Omar TahriIn Medical Imaging 2024: Image-Guided Procedures, Robotic Interventions, and Modeling , 2024
Wireless Capsule Endoscopy (WCE) is an emerging diagnostic technology to examine the Gastrointestinal tract and detect a wide range of diseases and pathologies by capturing images and transferring them remotely. The necessity of having control over the movement of the capsule is crucial to get more accurate detection of the location of the capsule, potential diseased areas, biopsy and drug delivery. However, several challenges are present for WCE, notably the deformable nature of the soft tissues, and texture-less surfaces which are subjected to strong specular reflections. To address these issues and since a reliable real-time 3D pose estimation is critical for controlling active endoscopic capsule robots, this work proposes a data-driven approach to estimate the pose and depth estimation of a wireless capsule endoscope. With recent advances in transformer networks in computer vision tasks, we introduce a Transformer-based architecture to use the self-attention mechanism for specular reflections and deformable topography of the Gastrointestinal tract. This would be a step toward developing a fully autonomous capsule endoscopy for more precise diagnostics and treatments.
@inproceedings{10.1117/12.3006235, author = {Nazifi, Nahid and Araujo, Helder and Erabati, Gopi Krishna and Tahri, Omar}, title = {{Self-supervised monocular pose and depth estimation for wireless capsule endoscopy with transformers}}, volume = {12928}, booktitle = {Medical Imaging 2024: Image-Guided Procedures, Robotic Interventions, and Modeling}, editor = {Siewerdsen, Jeffrey H. and Rettmann, Maryam E.}, organization = {International Society for Optics and Photonics}, publisher = {SPIE}, pages = {1292816}, keywords = {pose estimation, depth estimation, wireless capsule endoscopy, transformers, deep learning, localization, WCE, visual odometry}, year = {2024}, doi = {10.1117/12.3006235}, url = {https://doi.org/10.1117/12.3006235}, }






2023
- 3DObjDet-LiDAR
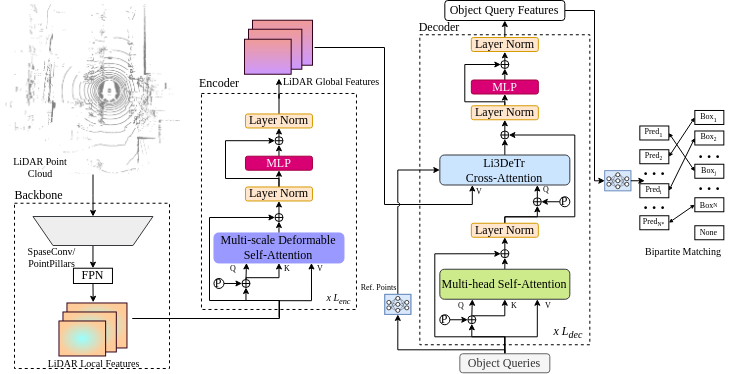 Li3DeTr: A LiDAR Based 3D Detection TransformerGopi Krishna Erabati, and Helder AraujoIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , 2023
Li3DeTr: A LiDAR Based 3D Detection TransformerGopi Krishna Erabati, and Helder AraujoIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , 2023Inspired by recent advances in vision transformers for object detection, we propose Li3DeTr, an end-to-end LiDAR based 3D Detection Transformer for autonomous driving, that inputs LiDAR point clouds and regresses 3D bounding boxes. The LiDAR local and global features are encoded using sparse convolution and multi-scale deformable attention respectively. In the decoder head, firstly, in the novel Li3DeTr cross-attention block, we link the LiDAR global features to 3D predictions leveraging the sparse set of object queries learnt from the data. Secondly, the object query interactions are formulated using multi-head self-attention. Finally, the decoder layer is repeated Ldec number of times to refine the object queries. Inspired by DETR, we employ set-to-set loss to train the Li3DeTr network. Without bells and whistles, the Li3DeTr network achieves 61.3% mAP and 67.6% NDS surpassing the state-of-the-art methods with non-maximum suppression (NMS) on the nuScenes dataset and it also achieves competitive performance on the KITTI dataset. We also employ knowledge distillation (KD) using a teacher and student model that slightly improves the performance of our network.
@inproceedings{li3detr, author = {Erabati, Gopi Krishna and Araujo, Helder}, title = {Li3DeTr: A LiDAR Based 3D Detection Transformer}, booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2023}, pages = {4250-4259}, }

2022
- 3DObjDet-Fusion
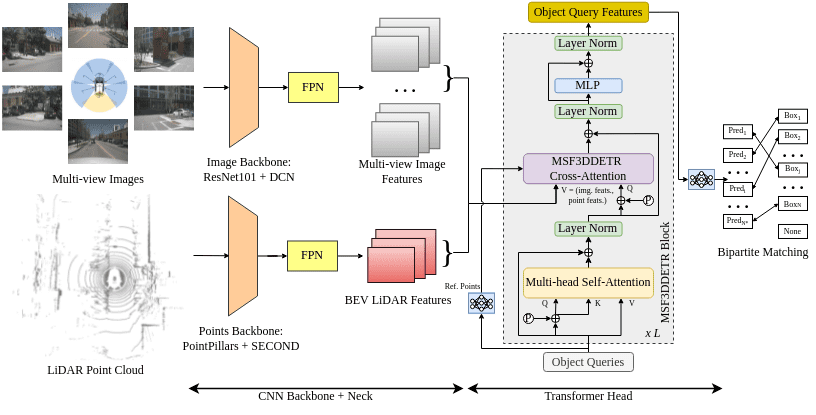 MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer for Autonomous DrivingGopi Krishna Erabati, and Helder AraujoIn ICPR 2022 workshop on Deep Learning for Visual Detection and Recognition (DLVDR) , Aug 2022
MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer for Autonomous DrivingGopi Krishna Erabati, and Helder AraujoIn ICPR 2022 workshop on Deep Learning for Visual Detection and Recognition (DLVDR) , Aug 20223D object detection is a significant task for autonomous driving. Recently with the progress of vision transformers, the 2D object detection problem is being treated with the set-to-set loss. Inspired by these approaches on 2D object detection and an approach for multi-view 3D object detection DETR3D, we propose MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer architecture to fuse image and LiDAR features to improve the detection accuracy. Our end-to-end single-stage, anchor-free and NMS-free network takes in multi-view images and LiDAR point clouds and predicts 3D bounding boxes. Firstly, we link the object queries learnt from data to the image and LiDAR features using a novel MSF3DDETR cross-attention block. Secondly, the object queries interacts with each other in multi-head self-attention block. Finally, MSF3DDETR block is repeated for L number of times to refine the object queries. The MSF3DDETR network is trained end-to-end on the nuScenes dataset using Hungarian algorithm based bipartite matching and set-to-set loss inspired by DETR. We present both quantitative and qualitative results which are competitive to the state-of-the-art approaches.

2021
- Moving Obj Seg
 MOSNet: A lightweight Moving Object Segmentation Network for Autonomous DrivingGopi Krishna Erabati, and Helder AraujoIn RECPAD 2021 - 27th Portuguese Conference on Pattern Recognition , Aug 2021
MOSNet: A lightweight Moving Object Segmentation Network for Autonomous DrivingGopi Krishna Erabati, and Helder AraujoIn RECPAD 2021 - 27th Portuguese Conference on Pattern Recognition , Aug 2021The ability to segment moving objects like cars is a very crucial element of visual perception system of autonomous vehicles for safe manoeuvrability of vehicles. In this paper, we aim to propose a light-weight Moving Object Segmentation Network (MOSNet) which adapts a two-stream architecture to extract appearance and motion features from RGB images and optical flow respectively. The extracted features are fused with the help of a fusion transformer, a Feature Pyramid Network (FPN) head is used to combine feature maps at various scales and further they are bilinearly upsampled to get back to the original dimension of the input which produces per-pixel class. The network is trained and tested on publicly available KITTI MOD dataset. It is shown that the proposed architecture achieves the Intersection over Union (IoU) of 48.89 % for moving objects and also runs at 50 fps on a RTX 2080 Ti GPU using a ShuffleNetV2 backbone.
@inproceedings{mosnet, author = {Erabati, Gopi Krishna and Araujo, Helder}, title = {MOSNet: A lightweight Moving Object Segmentation Network for Autonomous Driving}, booktitle = {RECPAD 2021 - 27th Portuguese Conference on Pattern Recognition}, pages = {7-8}, year = {2021}, }

2020
- 2DObjDetObject Detection in Traffic Scenarios - A Comparison of Traditional and Deep Learning ApproachesGopi Krishna Erabati, Nuno Gonçalves, and Helder AraujoIn Proceedings of 9th International Conference on Advanced Information Technologies and Applications (ICAITA 2020) , Aug 2020
In the area of computer vision, research on object detection algorithms has grown rapidly as it is the fundamental step for automation, specifically for self-driving vehicles. This work presents a comparison of traditional and deep learning approaches for the task of object detection in traffic scenarios. The handcrafted feature descriptor like Histogram of oriented Gradients (HOG) with a linear Support Vector Machine (SVM) classifier is compared with deep learning approaches like Single Shot Detector (SSD) and You Only Look Once (YOLO), in terms of mean Average Precision (mAP) and processing speed. SSD algorithm is implemented with different backbone architectures like VGG16, MobileNetV2 and ResNeXt50, similarly YOLO algorithm with MobileNetV1 and ResNet50, to compare the performance of the approaches. The training and inference is performed on PASCAL VOC 2007 and 2012 training, and PASCAL VOC 2007 test data respectively. We consider five classes relevant for traffic scenarios, namely, bicycle, bus, car, motorbike and person for the calculation of mAP. Both qualitative and quantitative results are presented for comparison. For the task of object detection, the deep learning approaches outperform the traditional approach both in accuracy and speed. This is achieved at the cost of requiring large amount of data, high computation power and time to train a deep learning approach.
- 3DObjDet-Fusion
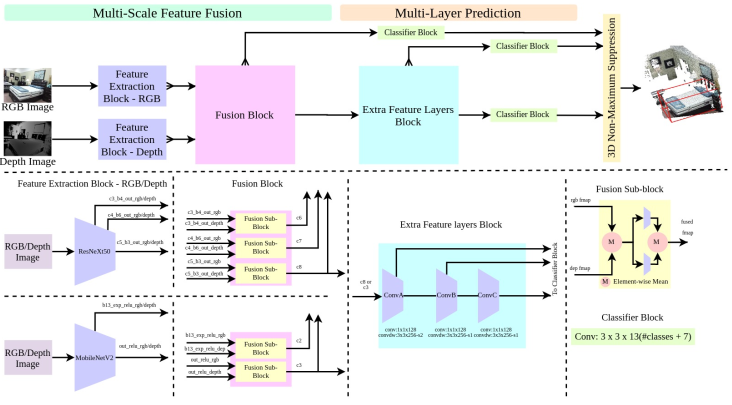 SL3D - Single Look 3D Object Detection based on RGB-D ImagesGopi Krishna Erabati, and Helder AraujoIn 2020 Digital Image Computing: Techniques and Applications (DICTA) , Nov 2020
SL3D - Single Look 3D Object Detection based on RGB-D ImagesGopi Krishna Erabati, and Helder AraujoIn 2020 Digital Image Computing: Techniques and Applications (DICTA) , Nov 2020We present SL3D, Single Look 3D object detection approach to detect the 3D objects from the RGB-D image pair. The approach is a proposal free, single-stage 3D object detection method from RGB-D images by leveraging multi-scale feature fusion of RGB and depth feature maps, and multi-layer predictions. The method takes pair of RGB and depth images as an input and outputs predicted 3D bounding boxes. The neural network SL3D, comprises of two modules: multi-scale feature fusion and multi-layer prediction. The multi-scale feature fusion module fuses the multi-scale features from RGB and depth feature maps, which are later used by the multi-layer prediction module for 3D object detection. Each location of prediction layer is attached with a set of predefined 3D prior boxes to account for varying shapes of 3D objects. The output of the network regresses the predicted 3D bounding boxes as an offset to the set of 3D prior boxes and duplicate 3D bounding boxes are removed by applying 3D non-maximum suppression. The network is trained end-to-end on publicly available SUN RGB-D dataset. The SL3D approach with ResNeXt50 achieves 31.77 mAP on SUN RGB-D test dataset with an inference speed of approximately 4 fps, and with MobileNetV2, it achieves approximately 15 fps with a reduction of around 2 mAP. The quantitative results show that the proposed method achieves competitive performance to state-of-the-art methods on SUN RGB-D dataset with near real-time inference speed.

2019
- 2DObjDet
 Dynamic Obstacle Detection in Traffic EnvironmentsGopi Krishna Erabati, and Helder AraujoIn Proceedings of the 13th International Conference on Distributed Smart Cameras , Trento, Italy, Nov 2019
Dynamic Obstacle Detection in Traffic EnvironmentsGopi Krishna Erabati, and Helder AraujoIn Proceedings of the 13th International Conference on Distributed Smart Cameras , Trento, Italy, Nov 2019The research on autonomous vehicles has grown increasingly with the advent of neural networks. Dynamic obstacle detection is a fundamental step for self-driving vehicles in traffic environments. This paper presents a comparison of state-of-art object detection techniques like Faster R-CNN, YOLO and SSD with 2D image data. The algorithms for detection in driving, must be reliable, robust and should have a real time performance. The three methods are trained and tested on PASCAL VOC 2007 and 2012 datasets and both qualitative and quantitative results are presented. SSD model can be seen as a tradeoff for speed and small object detection. A novel method for object detection using 3D data (RGB and depth) is proposed. The proposed model incorporates two stage architecture modality for RGB and depth processing and later fused hierarchically. The model will be trained and tested on RGBD dataset in the future.
@inproceedings{10.1145/3349801.3357134, author = {Erabati, Gopi Krishna and Araujo, Helder}, title = {Dynamic Obstacle Detection in Traffic Environments}, year = {2019}, isbn = {9781450371896}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3349801.3357134}, doi = {10.1145/3349801.3357134}, booktitle = {Proceedings of the 13th International Conference on Distributed Smart Cameras}, articleno = {32}, numpages = {2}, location = {Trento, Italy}, series = {ICDSC 2019}, }

2016
- Microwave
 Particle-in-cell simulations of CC-TWT for radar transmittersLatha Christie, and Gopikrishna ErabatiIn 2016 International Symposium on Antennas and Propagation (APSYM) , Dec 2016
Particle-in-cell simulations of CC-TWT for radar transmittersLatha Christie, and Gopikrishna ErabatiIn 2016 International Symposium on Antennas and Propagation (APSYM) , Dec 2016TWT is one of the fundamental components in a Radar Transmitter and compared to Helix TWT, Coupled Cavity TWT (CCTWT) gives the highest power over a moderate bandwidth. A complete simulation of the TWT is very useful in avoiding iterations and failures in TWT development cycle. In this paper, the CCTWT designed in the X-band frequency range, has been simulated using the Eigen mode solver and the particle-in-cell solver of the three-dimensional software package, CST Microwave Studio. The slow wave structure along with the couplers is designed initially with the equivalent circuit approach and later optimized using the Eigen mode solver of CST MWS. The initial estimate of the total number of cavities and the number of cavities per section was obtained using large signal analysis which was later optimized using Particle-in-cell Solver of CST MWS. The Simulation predicted an output power of around 1 kW and 27 cavities.
@inproceedings{7929140, author = {Christie, Latha and Erabati, Gopikrishna}, booktitle = {2016 International Symposium on Antennas and Propagation (APSYM)}, title = {Particle-in-cell simulations of CC-TWT for radar transmitters}, year = {2016}, pages = {1-4}, doi = {10.1109/APSYM.2016.7929140}, month = dec, } - MicrowaveHomogeneous and inhomogeneous coupling structures for coupled cavity TWTSGopikrishna ErabatiIET Conference Proceedings, Jan 2016
Analysis and optimization of performance of coupling structures of Coupled Cavity Travelling Wave Tube (CC-TWT) that are used to feed and extract RF power into and from the TWT is presented. The design of coupling structures includes the design of hybrid cavity and the design of stepped impedance transformer for transforming the impedance of waveguide to that of the cavity. The stepped impedance transformer can be homogeneous or inhomogeneous based on the design of magnets near the coupling end of the tube. In this paper the design of both the coupling structures. In this paper, the complete design of the coupling structure for coupled cavity TWT using the hybrid cavities and the stepped impedance transformer, both the homogeneous and the inhomogeneous type is presented. The analytical design is compared with that of 3-Dimensional (3D) electromagnetic simulation software, CST Microwave Studio (MWS) and the results presented.
@article{iet:/content/conferences/10.1049/cp.2016.1523, author = {Erabati, Gopikrishna}, affiliation = {Microwave Tube R&D Centre, Bangalore}, keywords = {3-Dimensional electromagnetic simulation software;inhomogeneous coupling structures;homogeneous coupling structures;Coupled Cavity Travelling Wave Tube;stepped impedance transformer;coupled cavity TWTS;coupling structure;CST Microwave Studio;hybrid cavity;}, language = {English}, title = {Homogeneous and inhomogeneous coupling structures for coupled cavity TWTS}, journal = {IET Conference Proceedings}, year = {2016}, month = jan, pages = {-(1)}, publisher = {Institution of Engineering and Technology}, url = {https://digital-library.theiet.org/content/conferences/10.1049/cp.2016.1523}, } - MicrowaveAnalysis of H-Plane Discontinuity in a Rectangular Waveguide using Mode Matching TechniqueLatha Christie, Payel Mondal, Sritama Dutta, and Gopikrishna ErabatiINROADS- An International Journal of Jaipur National University, Jan 2016
Accurate determination of S-parameters using Mode Matching Technique of H-plane discontinuity is presented. The generalized scattering matrix is obtained from the respective field equations. The H-plane discontinuity operating in X-Band has been considered for a case study. The results that have been obtained using Mode Matching Technique are compared with equivalent circuit approach and 3-D EM simulation software CST MWS and HFSS which are based on Finite Integration Technique and Finite Element Method respectively, based on accuracy and simulation time. The error between Mode Matching Technique and CST MWS is found to be less than 1% with the lowest simulation time.
@article{mondalanalysis, author = {Christie, Latha and Mondal, Payel and Dutta, Sritama and Erabati, Gopikrishna}, title = {Analysis of H-Plane Discontinuity in a Rectangular Waveguide using Mode Matching Technique}, journal = {INROADS- An International Journal of Jaipur National University}, year = {2016}, vol = {5}, issue = {1s}, pages = {367-371}, doi = {http://dx.doi.org/10.5958/2277-4912.2016.00069.2}, }

2015
- Microwave
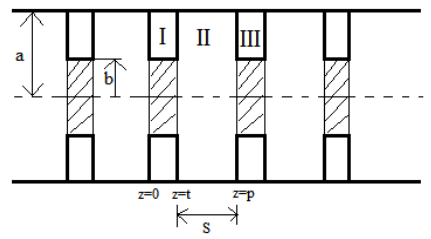 Analysis of Propagation Characteristics of Circular Waveguide Loaded with Dielectric Disks Using Coupled Integral Equation TechniqueLatha Christie, Gopikrishna Erabati, and Mita JanaIn 2015 Fifth International Conference on Advances in Computing and Communications (ICACC) , Sep 2015
Analysis of Propagation Characteristics of Circular Waveguide Loaded with Dielectric Disks Using Coupled Integral Equation TechniqueLatha Christie, Gopikrishna Erabati, and Mita JanaIn 2015 Fifth International Conference on Advances in Computing and Communications (ICACC) , Sep 2015Coupled Integral Equation Technique (CIET) is presented for the study of propagation characteristics of circular waveguide periodically loaded with dielectric disks operating in TM01d mode. CIET is a combination of Mode Matching Technique (MMT) and Method of Moments. The results are presented for three materials having different dielectric constants and compared with 3D simulation tool CST Studio in terms of simulation time and accuracy.
@inproceedings{7433812, author = {Christie, Latha and Erabati, Gopikrishna and Jana, Mita}, booktitle = {2015 Fifth International Conference on Advances in Computing and Communications (ICACC)}, title = {Analysis of Propagation Characteristics of Circular Waveguide Loaded with Dielectric Disks Using Coupled Integral Equation Technique}, year = {2015}, pages = {231-234}, doi = {10.1109/ICACC.2015.115}, month = sep, } - MicrowaveTransverse Focusing Structure for TWTsMita Jana, Latha Christie, and Gopikrishna ErabatiIn 11th International Conference on Microwaves, Antenna, Propagation and Remote Sensing (ICMARS 2015) , Dec 2015
@inproceedings{7433813, author = {Jana, Mita and Christie, Latha and Erabati, Gopikrishna}, booktitle = {11th International Conference on Microwaves, Antenna, Propagation and Remote Sensing (ICMARS 2015)}, title = {Transverse Focusing Structure for TWTs}, year = {2015}, pages = {52-53}, month = dec, }
